
机器学习与传统软件不同,后者像一种食谱。软件接收数据,根据清晰的描述进行处理,并产生结果,就像某人收集原料并按照食谱加工,制作蛋糕一样。与此相反,在机器学习中,计算机通过示例学习,使其能够处理过于模糊和复杂而无法通过逐步指令管理的问题。一个例子是解释图片以识别其中的物体。
1980 年,霍普菲尔德离开了他在普林斯顿大学的工作岗位,因为他的研究兴趣使他离开了物理学界同事工作的领域,来到了美国大陆的另一端。他接受了位于加利福尼亚州南部帕萨迪纳市的加州理工学院(Caltech)化学和生物学教授的聘书。在那里,他可以使用计算机资源进行自由实验,并发展他关于神经网络的想法。
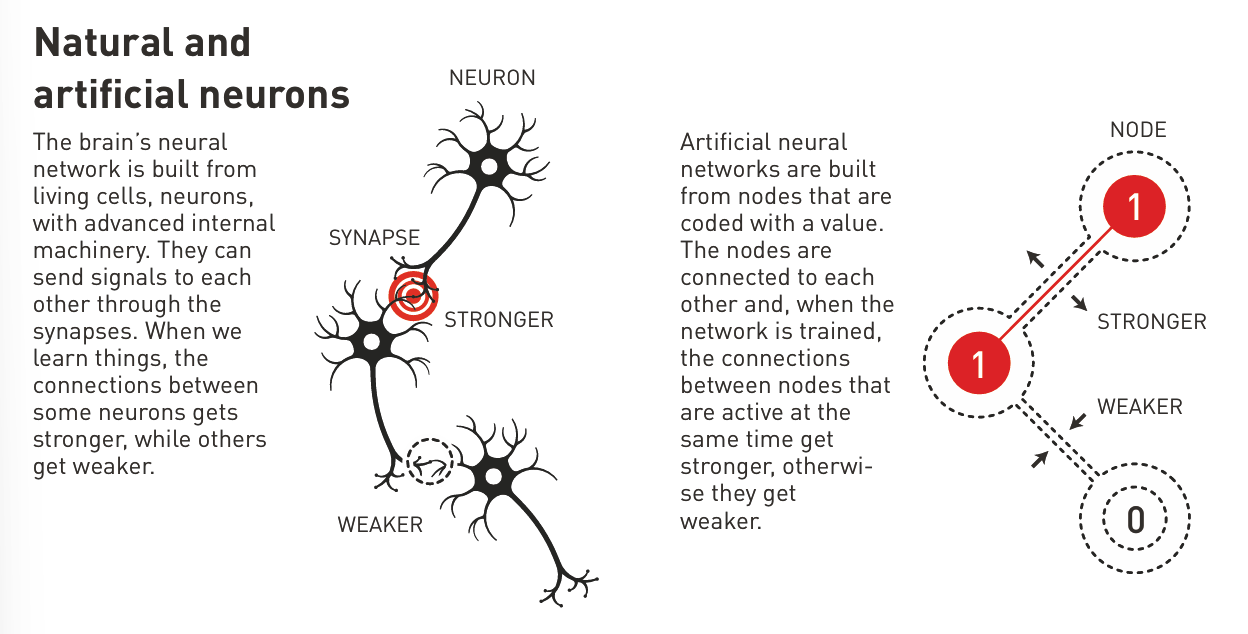
不过,他并没有放弃物理学的基础,因为在物理学中,他找到了灵感,理解了由许多小部件组成的系统如何协同工作,从而产生新的有趣现象。他尤其受益于对磁性材料的了解,这些材料因其原子自旋而具有特殊的特性——这种特性使每个原子都成为一块微小的“磁铁”。相邻原子的自旋(spin)会相互影响,从而形成自旋方向相同的磁畴(domain)。他利用描述自旋相互影响时材料如何发展的物理学原理,制作了一个具有节点和连接的模型网络。
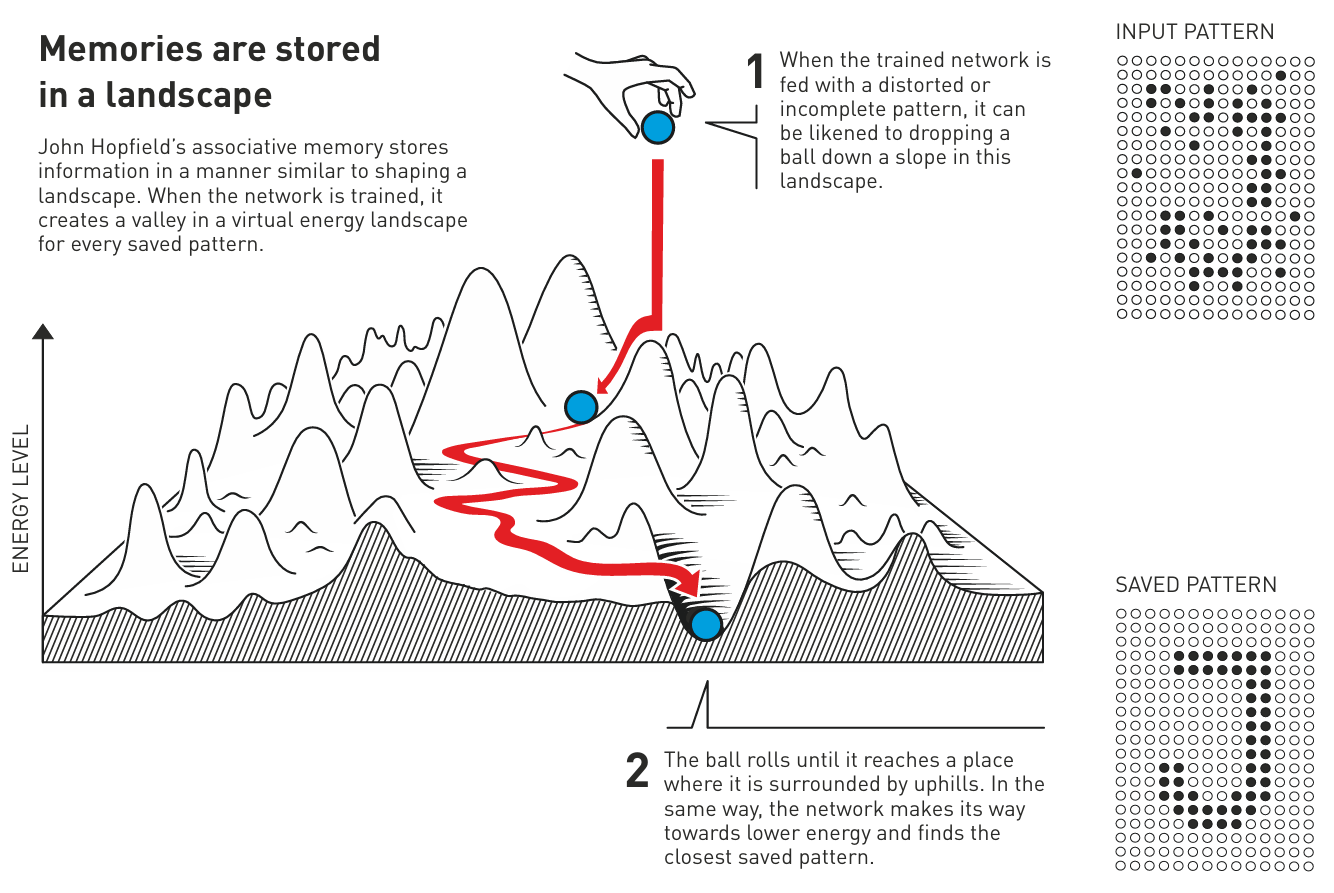
霍普菲尔德将搜索网络以找到保存的状态比作在有摩擦减缓其运动的山峰和山谷的景观中滚动一个球。如果球被放在一个特定的位置,它会滚进最近的山谷并停在那里。如果网络被给出了一个接近保存的模式的模式,它将以同样的方式继续前进,直到它在能量风景的山谷底部结束,从而找到记忆中最接近的模式。
霍普菲尔德网络可以用来重建包含噪声或已被部分删除的数据。
霍普菲尔德和其他人继续开发霍普菲尔德网络功能的细节,包括可以存储任何值的节点,而不仅仅是 0 或 1。如果把节点想象成图片中的像素,它们可以有不同的颜色,而不仅仅是黑或白。改进后的方法可以保存更多的图片,即使它们非常相似,也能区分开来。只要是由许多数据点构建的信息,就同样可以识别或重建任何信息。
统计物理学描述的是由许多相似元素组成的系统,例如气体中的分子。追踪气体中所有独立的分子是困难的,或者说是不可能的,但可以将它们视为一个整体来确定气体的总体特性,如压力或温度。气体分子以各自的速度在其体积中扩散,但仍能产生相同的集体特性,这其中有许多潜在的方法。
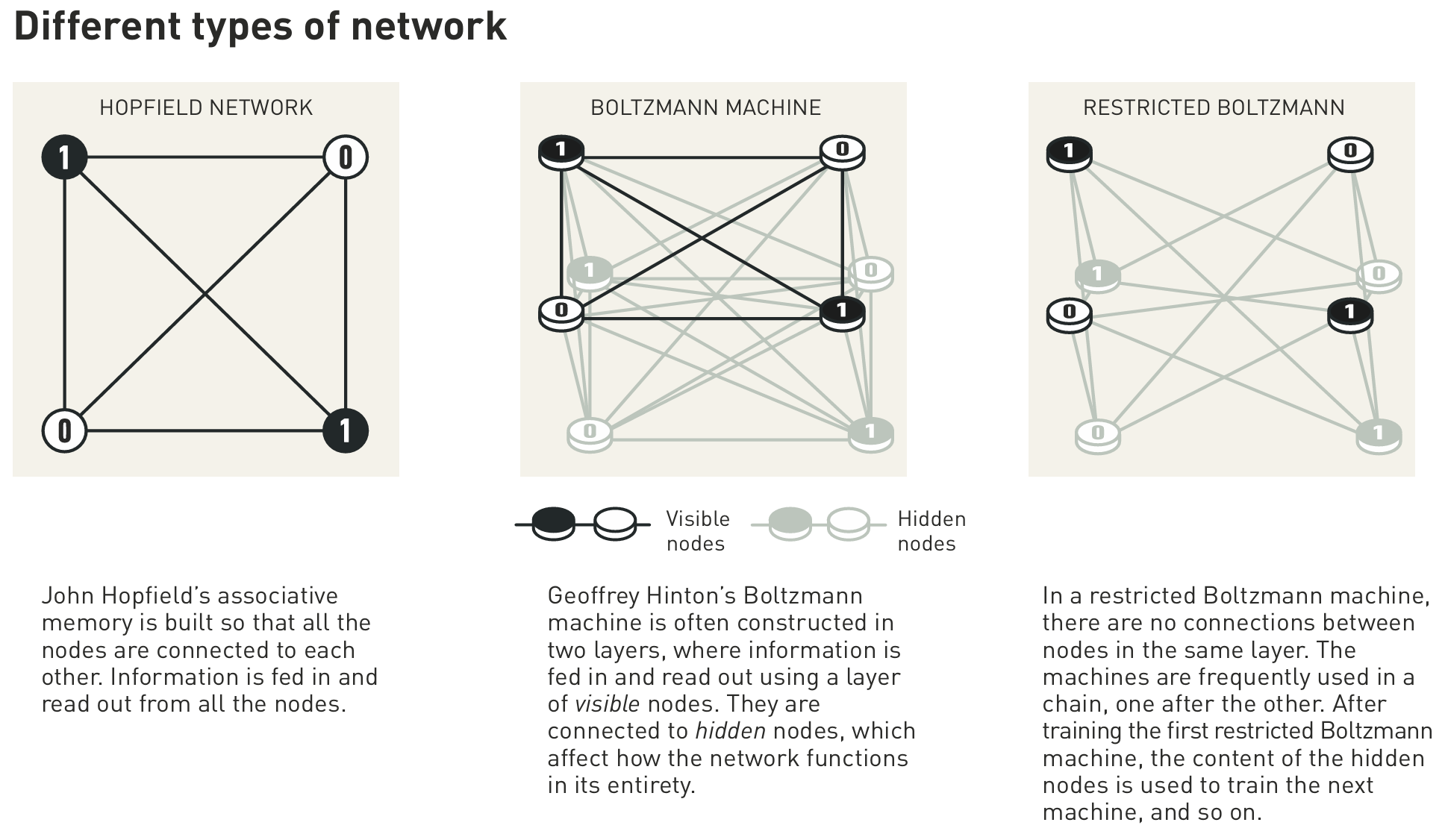
可以使用统计物理学分析个别组件可以共同存在的状态,并计算它们发生的概率。有些状态比其他状态更有可能发生,这取决于可用能量的大小,十九世纪物理学家路德维希·玻尔兹曼(Ludwig Boltzmann)曾用一个方程式来描述这种情况。辛顿的网络利用了那个方程,该方法在1985年以“玻尔兹曼机器Boltzmann machine”的名字发表。
训练有素的玻尔兹曼机器可以识别它以前从未见过的信息中熟悉的特征。想象一下见到朋友的兄弟姐妹,你可以立即看出他们一定是亲戚。类似地,如果一个全新的例子属于训练材料中的某个类别,玻尔兹曼机器就能识别出它,并将它与不相似的材料区分开来。
在其原始形式中,玻尔兹曼机器相当低效,需要很长时间才能找到解决方案。当它以各种方式发展时,情况就变得更加有趣了,而辛顿一直在探索这些方式。后来的版本被精简了,因为一些单元之间的连接被移除了。事实证明,这可能会使机器更高效。
在20世纪90年代,许多研究人员对人工神经网络失去了兴趣,但辛顿是继续在该领域工作的人之一。他还帮助启动了新一波激动人心的结果;在2006年,他和他的同事西蒙·奥辛德罗(Simon Osindero),易怀德(Yee Whye Teh)和鲁斯兰·萨拉赫特迪诺夫(Ruslan Salakhutdinov)开发了一种方法,通过一系列层次化的玻尔兹曼机器进行预训练。这种预训练为网络的连接提供了一个更好的起点,从而优化了识别图片中元素的训练。
玻尔兹曼机器通常作为更大网络的一部分使用。例如,它可以用于根据观众的偏好推荐电影或电视剧。
目前,许多研究人员正在开发机器学习的应用领域。哪一个领域最可行还有待观察,而围绕这项技术的开发和使用的伦理问题也引起了广泛的讨论。
物理学为机器学习的发展提供了工具,因此,我们不妨来看看物理学作为一个研究领域是如何从人工神经网络中获益的。长期以来,机器学习一直被应用于我们可能从以往的诺贝尔物理学奖中熟悉的领域。其中包括利用机器学习筛选和处理发现希格斯粒子所需的大量数据。其他应用还包括在测量黑洞碰撞产生的引力波或寻找系外行星时减少噪音。
近年来,这种技术也开始用于计算和预测分子和材料的特性,例如计算决定其功能的蛋白质分子结构,或找出哪种新材料具有最佳特性来提高太阳能电池的性能。
